一、sinx 泰勒展开的C实现
1.sinx 泰勒展开公式
sinx 的泰勒展开如下:
$$ sinx = x - \frac{x^3}{3!} + \frac{x^5}{5!} - \frac{x^7}{7!} + … + \frac{(-1)^n}{(2n + 1)!}x^{2n+1} $$
其中 n 从 0 开始计算,我采用的公式形态上是 $x=0$ 处的泰勒展开。实际上我们可以把 $x$ 写成 $x = x + x_0$ 来实现 $x=x_0$ 处的展开
2.C实现sinx泰勒展开
我们通过控制精度来控制展开项数,并且我们只考虑 $0-2\pi$ 的范围,归一化处理我们之后再详细考虑,通过泰勒展开公式我们的 C 程序如下:
#include <math.h>
#define degree 1e-2
float fun_sin(float x)
{
float res, term;
int i;
int factor; // 阶乘
term = x; // 每一项的结果
factor = 1;
res = term;
for (i = 1; fabs(term) > degree; i++)
{
factor *= (2 * i) * (2 * i + 1);
term = pow(-1, i) * pow(x, 2 * i + 1) / factor;
res += term;
}
return res;
}
上面的代码基本是严格按照公式计算的,可惜的是它并不能正常工作,这涉及到计算阶乘时整数溢出的问题。当输入比较小,比如 0.2,那么大概在第二项就达到了我们设定的精度 0.01 了,此时 factor 为 6,但是如果输入为 6.23 左右时,我们要计算 10 项以上才能达到我们设定的精度,第 10 项需要计算 21 的阶乘,即便使用 64 位无符号整型存储也不够,因此我们需要对其进行一定的优化。
二、sinx 泰勒展开优化
1.通过固定计算的阶数来保证不溢出
很容易想到的一点就是我们可以通过固定展开的项数来保证计算过程不会溢出,比如我们固定每次展开项数为 7,C 程序如下:
#include <math.h>
#define TIMES 7
float fun_sin(float x)
{
float res, term;
int i;
unsigned long factor;
factor = 1;
res = x;
for (i = 1; i < TIMES; i++)
{
factor *= (2 * i) * (2 * i + 1);
res += pow(-1, i) * pow(x, 2 * i + 1) / factor;
}
return res;
}
经测试,该程序在 $0-2\pi$ 内不会出现精度溢出的问题
2.从公式出发改变实现方法
观察 sinx 的泰勒展开我们可以得到如下规律:
- 记第 i 项展开式为 $a_i = \frac{(-1)^i}{(2i + 1)!}x^{2i+1}$
- 则有 $a_i = a_{i-1} \cdot \frac{-x^2}{(2i)\cdot(2i+1)}$
我们可以看出相邻两项相差一个乘积因子 $\frac{-x^2}{(2i)\cdot(2i+1)}$,而且这个因子中不会产生太大的数据导致数据溢出。这样我们可以保留通过精度控制展开项数的方法,而且不会产生数据溢出。实现的 C 程序如下:
#include <math.h>
#define pi 3.14159265
#define degree 1e-2 // ̩精度设置
const float factor_diff_mem[10] = // 乘积因子的分母部分
{
1.0, 1.0 / 6, 1.0 / 20, 1.0 / 42, 1.0 / 72,
1.0 / 110, 1.0 / 156, 1.0 / 210, 1.0 / 272, 1.0 / 342
};
float fun_sin(float x)
{
float sum;
float diff;
int i;
float term;
sum = x;
term = x; // 展开的每一项
diff = -1 * x * x; //乘积因子的分子部分
for (i = 1; fabs(term) > degree; i++)
{
term *= diff * factor_diff_mem[i];
sum += term;
}
return sum;
}
这里我们也做了一些优化,我们不再在 for 循环中去计算因子的分母部分,而是在编译阶段直接计算出,程序运行时直接查表即可,这也是经典的空间换时间的优化方式。可以看到现在这个程序已经没有指数和阶乘这种费时又可能导致溢出的计算了
三、三种方法时间比较
1.测试环境和代码
接下来我们将这两种方法和C标准库下的sinx进行时间上的比较,我采用的平台是 x86_64,Debian 12 系统,gcc 12.2,测试代码如下:
int get_us_time(){
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_usec;
}
int sinx_time_test(float (*fun_sin)(float), float *data, int n, int count)
{
int start, end;
float x;
int i, j;
start = get_us_time();
for (j = 0; j < count; j++) // 周期数量
{
for (i = 0; i <= n; i++)
{
x = 2 * pi * i / n; // 0-2pi取n个点
data[i] = fun_sin(x);
// printf("%f\n", data[i]);
}
}
end = get_us_time();
return end - start;
}
这里采用两层循环是为了更方便看到差距以外,还要保证一个周期内不要取太多点,导致输入的x精度过高,这里我们不对精度做太高要求。
2.程序运行时间对比
三种方法程序运行时间如下:
| C standard | Fixed degree | Fixed items |
|---|---|---|
| 184 us | 266 us | 1701 us |
多次运行数值上的结果可能不一样,但是三者的关系基本不变,标准库的 sinx 最快,其次是我们优化后的固定精度的实现,最后是固定周期的实现。我们可以看到优化后的固定精度的实现和 C 标准库执行时间差不多,只有几十us的差距,但是固定周期的实现方法运行的时间却是其他两种方法的 10 倍,可见其效率之低。
3.程序运行精度对比
我们借助 gnuplot 去绘制这三种方法的 sinx 曲线去大概对比精度,如图所示:
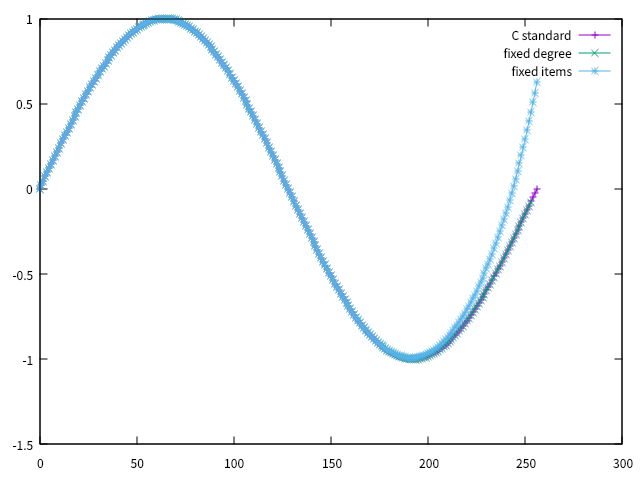
可以看到,当x逐渐变大时,固定周期的方法的精度已经出现非常明显的误差了,而我们优化后的固定精度的方法几乎是与标准库的实现完全重叠,甚至我们可以尝试继续调小精度来提升程序运行速度。
四、输入归一化处理
前面我们已经实现了速度接近标准库实现的泰勒展开,但是范围被限定在 $(-2\pi, 2\pi)$ 之间,其实我们也可以输入超过这个范围的数据,但是随着输入的绝对值的变大,为了保证相同的精度,泰勒展开项数会逐渐增多,程序运行速度会越来越慢,最后很有有可能导致精度再次溢出。我们不希望不同的输入对程序的运行状态有太大的影响。因此,我们需要对输入进行归一化处理。
1.归一化操作
归一化操作其实很简单,借助 sinx 的周期性,在本程序中归一化操作如下
const float T = 2 * pi; // sinx周期为2pi
float fun_sin(float x){
...
int n = (int)(x / T); // 计算周期数量
x -= n * T; // sin(x) = sinx(x - 2n*pi)
...
}
2.对除法的优化
在某些平台上,比如DSP芯片中,我们不希望程序中出现除法操作,因为除法是一个非常耗时的操作。在很多DSP芯片中加法和乘法是基本计算操作,cpu只需要一个指令就能完成,但是除法是非常耗时的,所以我们可以尝试改写一下,将其变成乘法的形式
const float T = 2 * pi
const float f = 1 / T // 编译阶段执行
float fun_sin(float x){
...
x -= T * (int)(x * f)
...
}
我们把涉及到除法的部分放到编译阶段执行,这样可以优化在某些不支持快速计算除法的平台上的运行速度。
3.对浮点数截断的操作
这个优化也是在DSP芯片的场景中,我们使用 int 类型强制转换来对浮点数进行截断操作,这句话看起来很简单,实际上是一个非常复杂的操作,因为浮点数的存储方式不像整型数据那样01排列然后根据二进制计算即可,浮点数有其自己的存储方式。你可以很容易通过整型数据的二进制去计算 10 进制,但是浮点数的二进制却不是那么容易计算。IEEE754标准就定义了浮点数在二进制中的存储格式,这里不做过多介绍。 总之知道存储格式后我们可以通过位运算去进行浮点数截断的操作,我之前在 CCS V5.5 仿真 TMS320VC5509A 芯片的平台上测试过,这个方法确实可以提升程序运行速度,甚至比库函数还快,但是在 x86 平台上几乎没有多少提升。(代码是参考网上一篇文章的,但是我忘记链接了…)
union FloatBit
{
float f;
int f_b;
} ret, bias;
int Float2Int(float f) // 快速转换浮点数为整数
{
ret.f = f;
bias.f_b = (23l + 127l) << 23;
if (f < 0.0f)
{
bias.f_b = ((23l + 127l) << 23) + (1l << 22);
}
ret.f += bias.f;
ret.f_b -= bias.f_b;
return ret.f_b;
}
需要注意你的平台上 int 位数应该和 float 一样都是 32 位,如果int是 16 位应该换成 long 或者其他 32 位的整型类型。
五、最终程序实现
最终我们优化完的程序如下:
#include <math.h>
#define pi 3.14159265
#define degree 1e-2 // ̩精度设置
const float factor_diff_mem[10] = // 泰勒展开因子
{
1.0, 1.0 / 6, 1.0 / 20, 1.0 / 42, 1.0 / 72,
1.0 / 110, 1.0 / 156, 1.0 / 210, 1.0 / 272, 1.0 / 342};
const float T = 2 * pi;
const float f = 1 / (2 * pi);
union FloatBit
{
float f;
int f_b;
} ret, bias;
int Float2Int(float f) // 快速转换浮点数为整数
{
ret.f = f;
bias.f_b = (23l + 127l) << 23;
if (f < 0.0f)
{
bias.f_b = ((23l + 127l) << 23) + (1l << 22);
}
ret.f += bias.f;
ret.f_b -= bias.f_b;
return ret.f_b;
}
float fun_sin(float x)
{
float sum;
float diff;
int i;
float term;
x -= T * Float2Int(x * f);
sum = x;
term = x;
diff = -1 * x * x;
for (i = 1; fabs(term) > degree; i++)
{
term *= diff * factor_diff_mem[i];
sum += term;
}
return sum;
}
我们尝试将输入 $x$ 改成 $x+b,b=100i, -100 < i < 100$,去将这个程序与 C 标准库程序对比,如图所示:
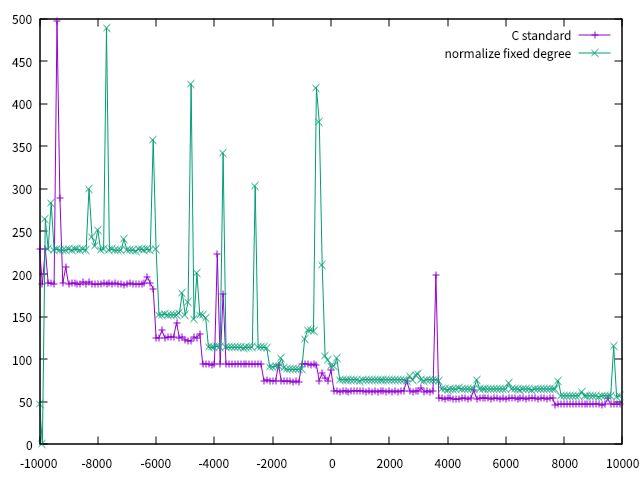
可以看到,两种方法在运行时间和稳定性上差距很小,我们的程序达到了我们预期的性能了